Lesson 21: Learning to Love XML
Lesson 21: Learning to Love XML
Objective:
Students will understand the need for data to be stored in different ways - specifically, why it makes sense for web data to be formatted as XML.
Materials:
-
Online Data-ing handout (LMR_U3_L20_C)
Note: This should have been completed during the previous class.
-
Mountain Peak XML data found at:
https://labs.idsucla.org/extras/webdata/mountains.htmlNote: Open with Google Chrome or Firefox browsers, NOT with Safari.
-
Mountains – HTML vs. XML handout (LMR_U3_L21)
-
XML Viewer found at:
https://jsonformatter.org/xml-viewer -
HTML Viewer found at:
https://jsonformatter.org/html-viewer -
Projector
Vocabulary:
Essential Concepts:
Essential Concepts:
XML is a programming language that we use with our campaigns. We create basic XML "tags" in the code, which help us store data in a format we understand.
Lesson:
-
Allow time for student teams to present their findings from the Online Data-ing handout (LMR_U3_L20_C) if there was not sufficient time during the previous lesson.
-
Remind students that in the previous lesson they learned about a variety of ways that data can be presented online.
-
They've been working with comma separated (CSV) files and R data frames. Last time and in the lab, they worked with HTML tables. Today they are going to learn how the data in tables built with HTML can be stored using XML.
-
XML, or Extensible Mark up Language, is a popular format for storing data on the Internet. It allows programmers to easily update values in a data table if those values change.
-
In pairs, ask students to brainstorm ways in which data that is found online is different than the way we see data in RStudio. Then, create a class brainstorm from the student pair responses.
-
After the brainstorm, emphasize the following:
-
RStudio’s default way to work with data is as large data frames (tables) where rows represent observations and columns represent variables.
-
Data that is viewed online often has a different structure.
-
Data structures found on the web might be displayed in tables, such as those on Wikipedia, or streams, such as Twitter, and might even include data spread across multiple sections of a web page, such as Yelp.
Show students, on a projector, the Mountain Peak XML data found at
https://labs.idsucla.org/extras/webdata/mountains.htmlAsk students to look at the data and determine if they have seen it before. Hint: They have! It was the data they scraped during Lab 3E.
-
-
Once students figure out that the XML is just the same data as the website they scraped during Lab 3E, distribute the Mountains – HTML vs. XML handout (LMR_U3_L21), which displays both HTML and XML versions of the data.
Note: Provide an electronic coopy of LMR_U3_L21 for students to easily copy/paste the code later in the lesson. The handout only includes the first 3 mountains.
-
Ask student pairs to answer the following:
-
Why are certain XML tags indented in the XML version of the data? Answer: The indentations help us visually see the structure of the data. For example, all the mountains are contained in the <data> section, but are further tagged by each particular mountain within the <mountain> and </mountain> tags. All information stored between those two tags will be displayed as one row of the HTML table.
-
What are the role of tags (ex. <state>) and end tags (ex. </state>) in the XML code? Answer: Tags tell us when a certain type of data begins, and end tags tell us when the data should end. In other words, it tells us where to find the specific values of a variable (ex. Alaska would be the value of the “state” variable since it is between the <state> and </state> tags).
-
Where are the variable names? Answer: The variable names can be found between each <mountain> and </mountain> tags. Specifically, the first variable is “peak” and the last variable is “rank.”
-
Where are the observations? Answer: The observations are located within each of the variable tags. For example, the observation “Denali (Mount McKinley)” is found between the <peak> and </peak> tags.
-
-
Assign student pairs one of the above questions to share out with the class. Student pairs that did not receive an assignment must participate using the Agree/Disagree strategy.
-
As a class, discuss the answers to the questions above.
-
Inform students that they will be comparing how HTML and XML code display by default.
-
Demonstrate how to navigate to the two websites we will be using to display the HTML and XML code by projecting the following URLs:
-
Inform students that they will be copying and pasting their XML code from the electronic copy of LMR_U3_L21 into the left "XML Viewer" (Input XML) panel as shown below.
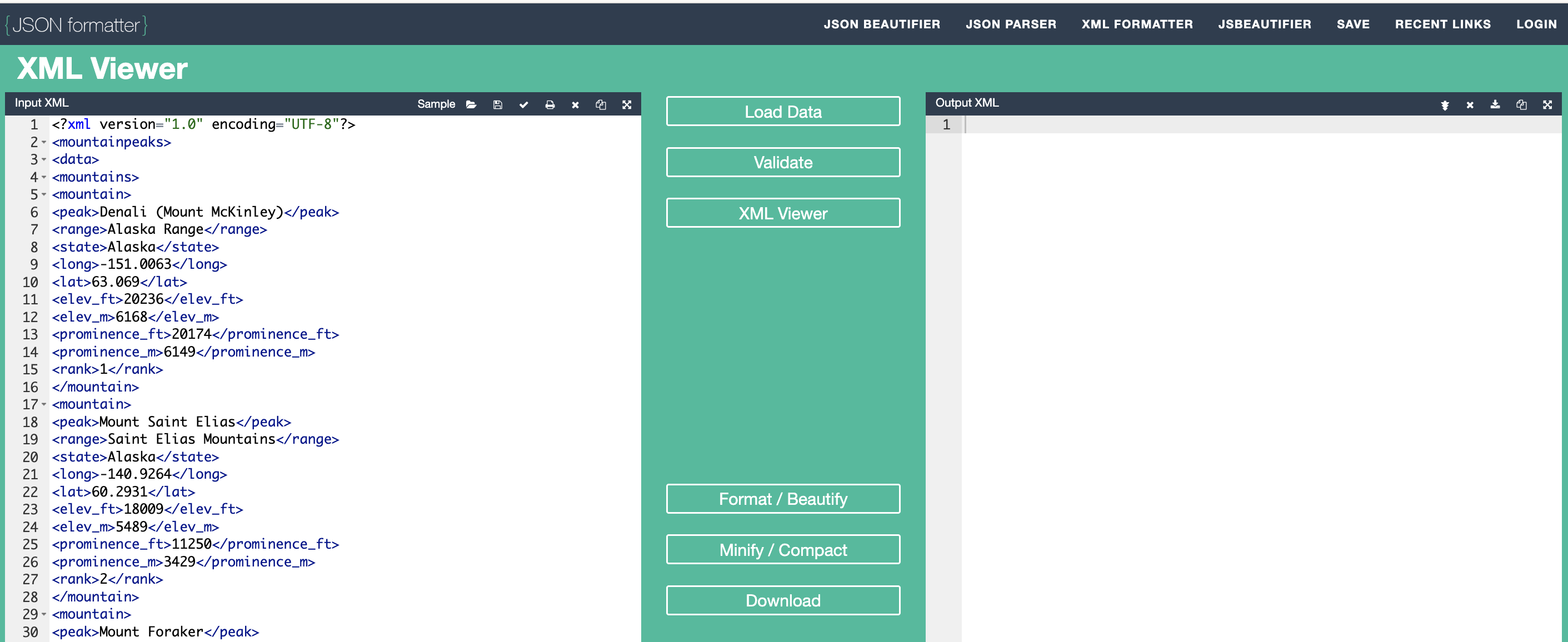
-
In order to view how the XML code displays, click "XML Viewer" in the center of the web page as shown below.
Note: Click on the dropdown arrows of the Output XML to explore how it is displayed
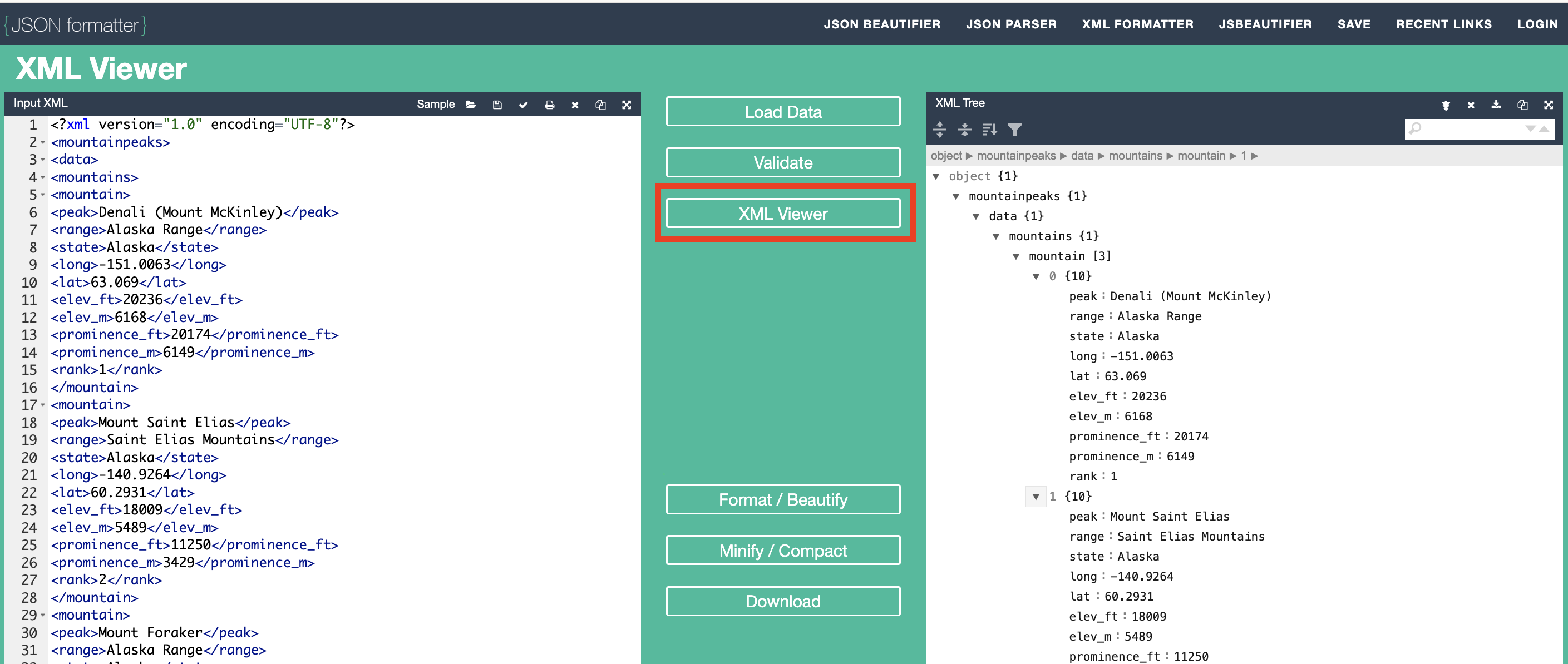
-
We want to compare how the XML code displays with how the HTML code displays. Inform students that they will now be copying and pasting their HTML code into the left "HTML Viewer" (Input HTML) panel as shown below.

-
In order to view how the HTML code displays, click "RUN" in the center of the web page as shown below.
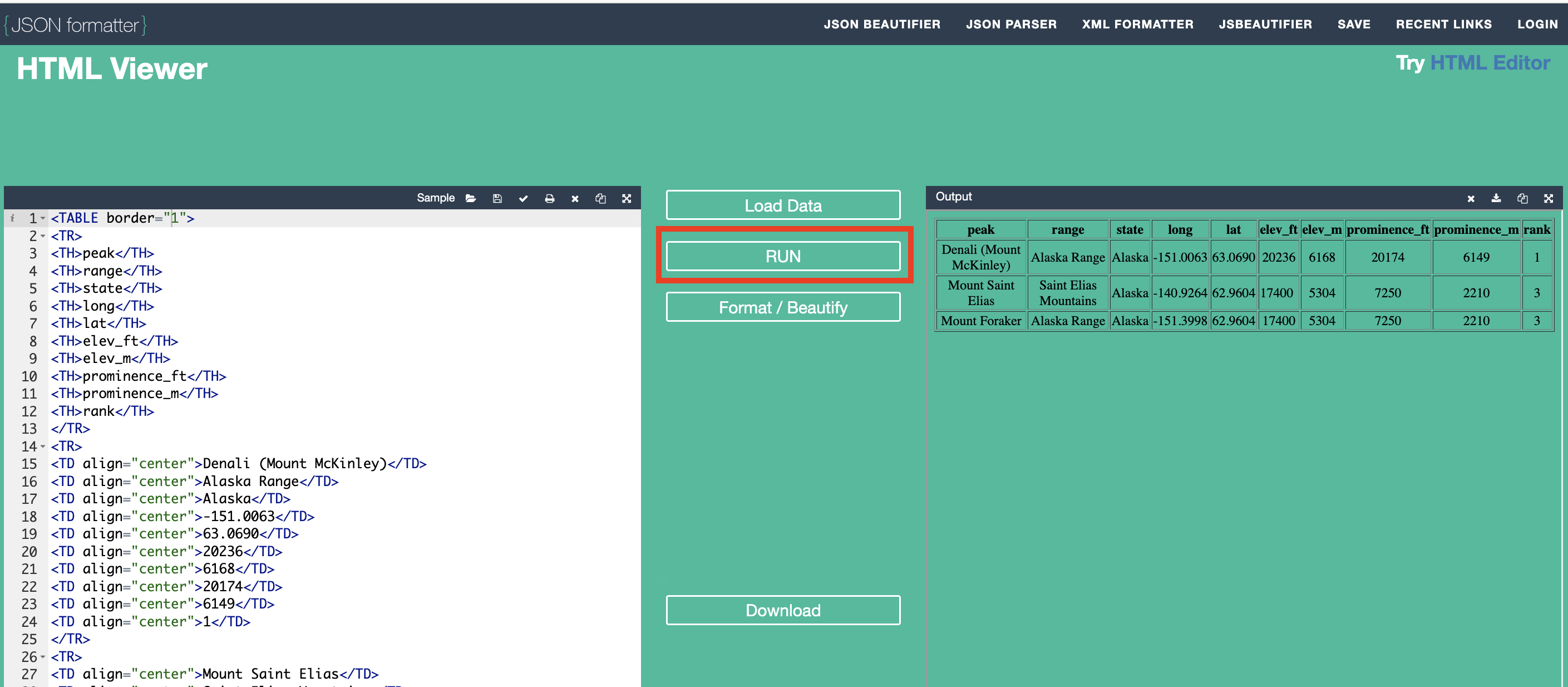
-
Examine the differences in how HTML and XML are displayed. Ask:
a. What do you notice? Answers will vary but students might notice that HTML is displayed as a table while XML displays the data in a list-like format. XML also has each data value tied to the variable name while HTML has one variable name for the three data values it represents.
b. How does the Output XML compare to the Output HTML? Possible answers might be that XML shows the data organized but not in any type of visualization/table while HTML is displayed as a table.
-
One of the benefits of XML is that removing a data point effectively removes it from the data file but does not necessarily change the integrity of the data - the variable names are still tied to the data values. Demonstrate this by removing a data point from the Input XML and then click "XML Viewer" again to see the updated Output XML.
Note: In the image below, the
<state>Alaska</state>data point has been removed.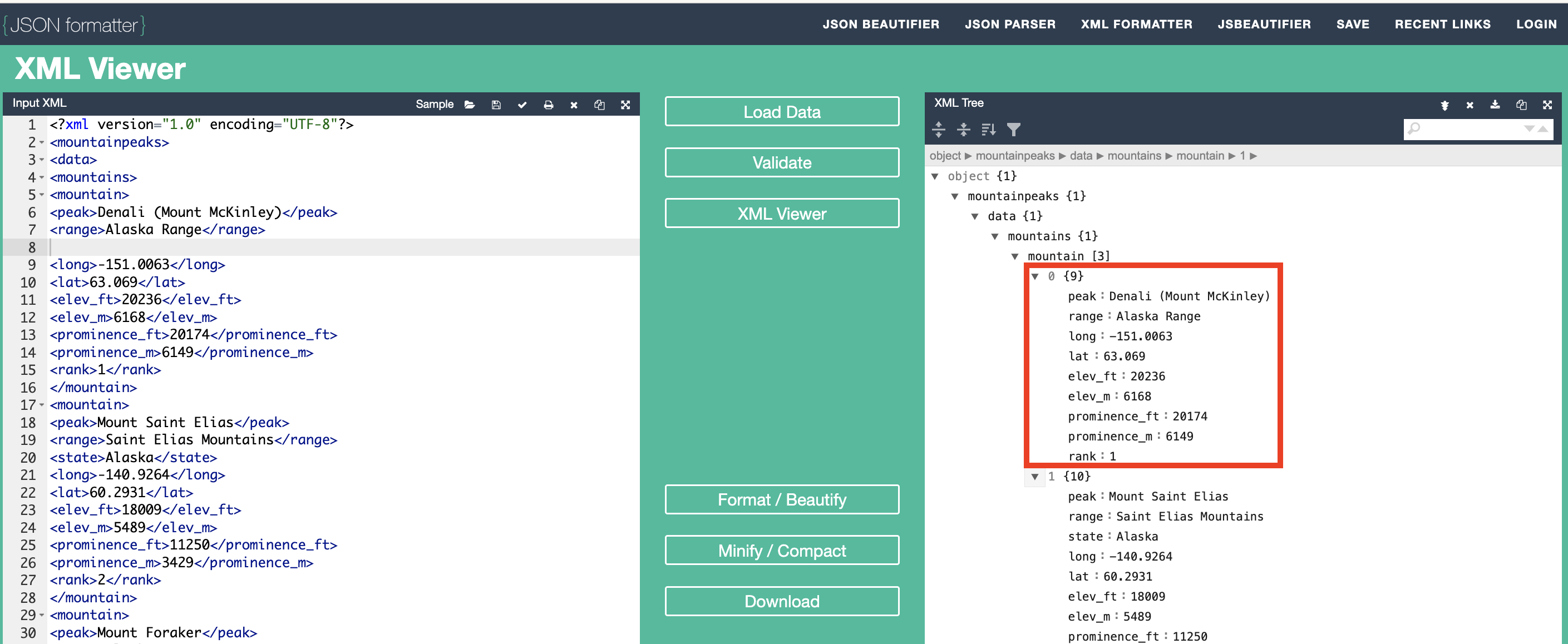
-
Examine the updated Output XML. Ask:
a. What changed when we removed a data point? Answer: The first section of mountain data now has 9 data values instead of 10.
b. Can we still analyze this data accurately? Answer: Yes, each data value is still tied to the variable name that represents it.
c. What do you think will happen when we remove a data point from our HTML code? Answers will vary.
-
Demonstrate removing a data point from the Input HTML and then click "RUN" again to see the updated Output HTML.
Note In the image below, the
<TD align="center">Alaska</TD>data point has been removed.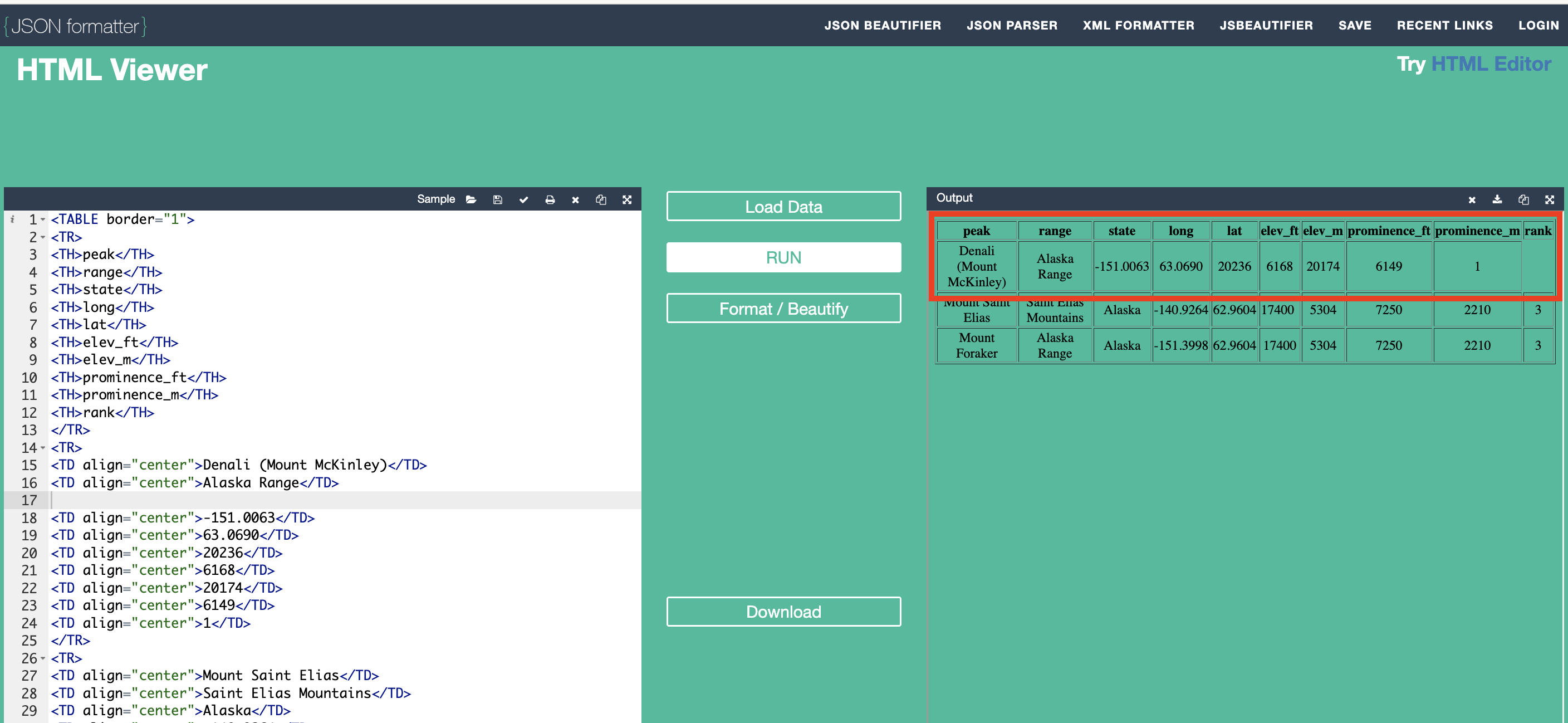
-
Examine the updated Output HTML. Ask:
a. What changed when we removed a data point? Answer: The table has a blank value at "rank" and it appears that all the data values in that row have shifted over – HTML skipped the missing data value and filled in the rest of the table with the data values given.
b. Can we still analyze this data accurately? Answer: No, starting with the "state" value that is missing, all of the values in the row shifted to the left ending up in the wrong columns.
-
Summarieze: XML formats make it easier to store data on the web in a pleasing manner and make it easier for programmers to find and alter data if the values change or if, for example, they wish to add a new row to a table. Depending on how the web page presents the XML (table, list, etc.), the consequences of changing the data vary on how the program is designed to display it.
Class Scribes:
One team of students will give a brief talk to discuss what they think the 3 most important topics of the day were.
Homework
For the next 3 days, students will collect data using the class’s newly created Participatory Sensing campaign (see Lessons 17-19).
For homework, students should reflect on the purpose of XML and HTML as it pertains to data.